Pub/Sub
Before we dive into Kafka let’s start with a quick recap on what publish/subscribe (pub/sub) messaging is.
Publish/subscribe is a messaging pattern where the sender (or the publisher) doesn’t send data directly to a specific receiver. Instead, the publisher classifies the messages without knowing if there are any subscribers interested in a particular type of messages. Similarly, the receiver subscribes to receive a certain class of messages without knowing if there are any senders sending those messages.
Pub/sub systems usually have a broker, where all messages are published. This decouples publishers from subscribers and allows for greater flexibility in the type of data that subscribers want to receive. It also reduces the number of potential connections between publishers and subscribers.
Bulletin board comes handy as a good analogy to a pub/sub messaging pattern, where people can publish information in a central place without knowing who the recipients are.
What is Kafka?
Okay, so what is Kafka then?
Apache Kafka is an open-source, publish/subscribe (pub/sub) messaging system, also very often described as a distributed event log where all the new records are immutable and appended to the end of the log.
In Kafka, messages are persisted on disk for a certain period of time known as the retention policy. This is usually the main difference between Kafka and other messaging systems and makes Kafka in some way a hybrid between a messaging system and a database.
The main concepts behind Kafka are producers producing messages to different topics and consumers consuming those messages and maintaining their position in the stream of data. You can think about producers as publishers or senders of messages. Consumers, on the other hand, are analogous to the receivers or subscribers.
Kafka aims to provide a reliable and high-throughput platform for handling real-time data streams and building data pipelines. It also provides a single place for storing and distributing events that can be fed into multiple downstream systems which helps to fight the ever-growing problem of integration complexity. Besides all of that Kafka can also be easily used to build a modern and scalable ETL, CDC or big data ingest systems.
Kafka is used across multiple industries, from companies like Twitter and Netflix to Goldman Sachs and Paypal. It was originally developed by Linkedin and open sourced in 2011.
Kafka Architecture
Now let’s dive a little bit deeper into the Kafka architecture.
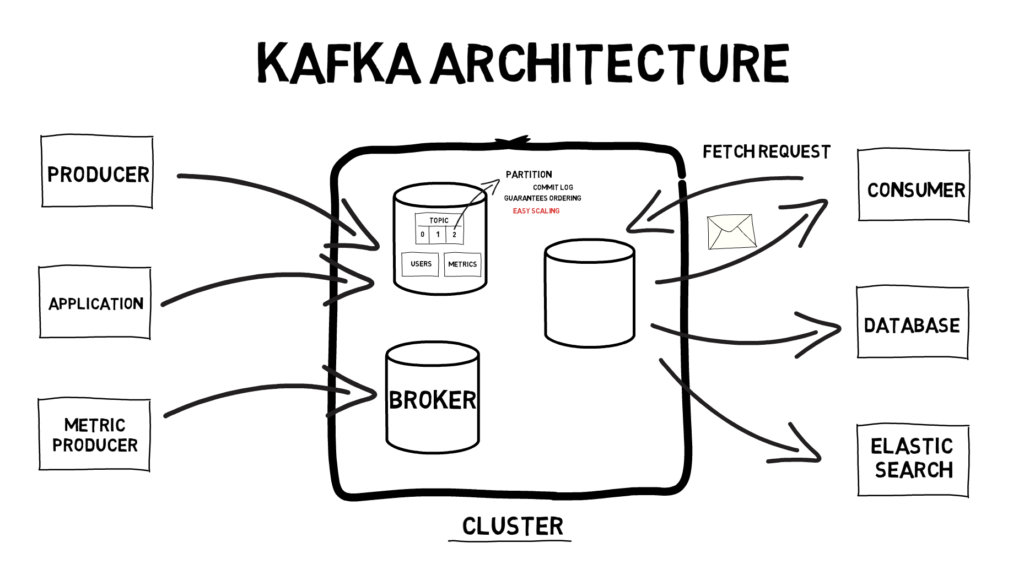
On a high level, usual Kafka architecture consists of a Kafka cluster, producers and consumers.
A single Kafka server within a cluster is called a broker. A Kafka cluster usually consists of at least 3 brokers to provide enough level of redundancy. The broker is responsible for receiving messages from producers, assigning offsets and committing messages to disk. It is also responsible for responding to consumers fetch requests and serving messages.
In Kafka, when messages are sent to a broker, they are sent to a particular topic. Topics provide a way of categorising data that is being sent and they can be further broken down into a number of partitions. For example, a system can have separate topics for processing new users and for processing metrics. Each partition acts as a separate commit log and the order of messages is guaranteed only across the same partition. Being able to split a topic into multiple partitions makes scaling easy as each partition can be read by a separate consumer. This allows for achieving high throughput as both partitions and consumers can be split across multiple servers.
Producers are usually other applications producing data. This can be, for example, our application producing metrics and sending them to our Kafka cluster.
Similarly, consumers are usually other applications consuming data from Kafka. As we mentioned before Kafka very often acts like a central hub for all the events in the system which means it’s a perfect place to connect to if we are interested in a particular type of data. A good example would be a database that can consume and persist messages or an elastic search cluster that can consume certain events and provide full-text search capabilities for other applications.
Messages, Batches, Schemas, Topics and Partitions
Now as we went through the general overview of Kafka, let’s jump into the nitty-gritty details.
In Kafka, a message is a single unit of data that can be sent or received. As far as Kafka is concerned, a message is just a byte array, so the data doesn’t have any special meaning to Kafka. A message can also have an optional key (also a byte array) that can be used to write data in a more controlled way to multiple partitions within the same topic.
As an example, let’s assume we want to write our data to multiple partitions as it will be easier to scale the system later. We realised that certain messages, let’s say for each user, have to be written in order. If our topic has multiple partitions, there is no guarantee which messages will be written to which partitions, most likely the new messages would be written to partitions in a round-robin fashion. To avoid that situation we can define a consistent way for choosing the same partition based on a message key. One way of doing that would as simple as using (user id) % (number of partitions) that would assign always the same partition to the same user.
Sending single messages over the network creates a lot of overhead, that’s why messages are written into Kafka in batches. A batch is a collection of messages produced for the same topic and partition. Sending messages in batches provides a trade-off between latency and throughput and can be further controlled by adjusting a few Kafka settings. Additionally, batches can be compressed which provides even more efficient data transfer.
Even though we already established that Kafka messages are just simple byte arrays, in most cases it makes sense to provide additional structure to the message content. There are multiple schema options available. The most popular ones are JSON, XML, Avro or Protobuf.
We already described what topics and partitions are, but let’s just emphasise again the importance of not having any guarantees when it comes to a message time-ordering across multiple partitions of the same topic. The only way to achieve the ordering for all messages is to have only one partition. By doing that we can be sure that events are always ordered by the time they were written into Kafka.
Another important concept when it comes to partitions is the fact that each partition can be hosted on a different server which means that a single topic can be scaled horizontally across multiple servers to improve the throughput.
Producers, Consumers, Offsets, Consumer Groups and Rebalancing
Kafka cluster wouldn’t be very useful without its clients who are the producers and consumers of the messages.
Producers create new messages and send them to a specific topic. If a partition is not specified and a topic has multiple partitions, messages would be written into multiple partitions evenly. This can be further controlled by having a consistent message key that we described earlier.
Consumers, on the other hand, read messages. They subscribe to one or multiple topics and read messages in the order they were produced. The consumer keeps track of its position in the stream of data by remembering what offset was already consumed. Offsets are created at a time a message is written to Kafka and they correspond to a specific message in a specific partition. Within the same topic, multiple partitions can have different offsets and it’s up to the consumer to remember what offset each partition is at. By storing offsets in Zookeeper or Kafka itself a consumer can stop and restart without losing its position in the stream of data.
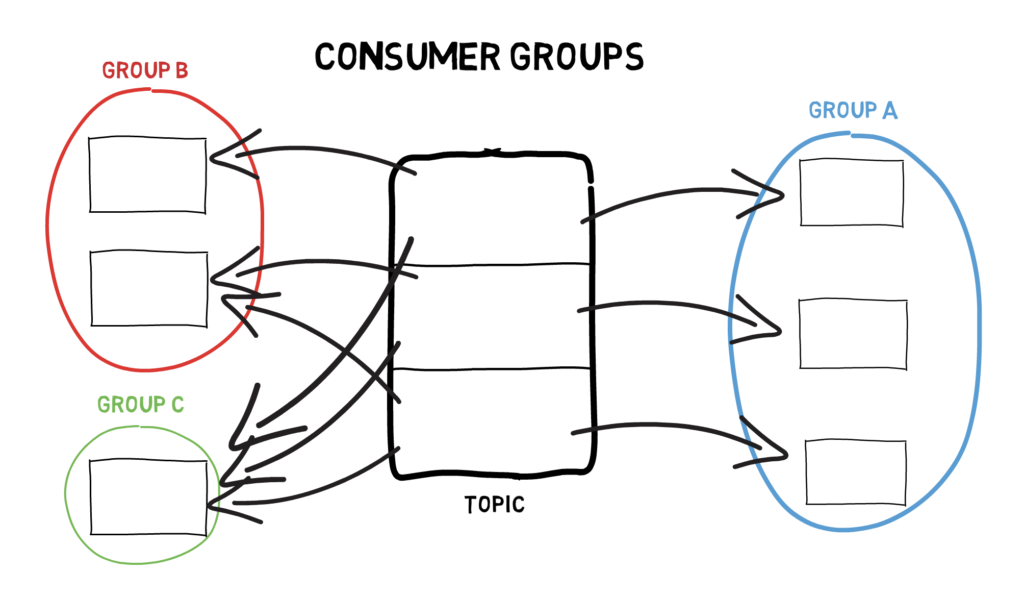
Consumers always belong to a specific consumer group. Consumers within a consumer group work together to consume a topic. The group makes sure that each partition is only consumed by one member of a consumer group.
This way, consumers can scale horizontally to consume topics with a large number of messages. Additionally, if a single consumer fails, the remaining members of the group will rebalance the partitions to make it up for the missing member.
In case we want to consume the same messages multiple times, we have to make sure the consumers belong to different consumer groups. This can be useful if we have multiple applications that have to process the same data separately.
Clusters, Brokers and Retention
As we mentioned before, Kafka cluster consists of multiple servers called brokers. Depending on the specific hardware, a single broker can easily handle thousands of partitions and millions of messages per second.
Kafka brokers are designed to operate as part of a cluster. Within a cluster of brokers, one broker will also act as the cluster controller (elected automatically). The controller is responsible for administrative operations, including assigning partitions to brokers and monitoring for broker failures. A partition is always owned by a single broker in the cluster, who is called the leader of the partition. A partition may be assigned to multiple brokers, which will result in the partition being replicated. This provides redundancy of messages in the partition, such that another broker can take over leadership if there is a broker failure. However, all consumers and producers operating on that partition must connect to the leader.
One of the key features of Kafka is retention, which, for some period of time, provides durable storage of messages. Kafka brokers are configured with a default retention setting for topics, either retaining messages for some period of time, 7 days by default or until the topic reaches a certain size in bytes e.g. 1GB. Once these limits are reached, the oldest messages are expired and deleted so that the retention configuration is a minimum amount of data available at any time. Individual topics can also configure their own retention settings. For example, a topic for storing metrics might have very short retention of a few hours. On the other hand, a topic containing bank transfers might have a retention policy of a few months.
Reliability Guarantees
Reliability is often discussed in terms of guarantees. These are certain behaviours of a system that should be preserved under different circumstances. Understanding those guarantees is critical for anyone trying to build reliable applications on the top of Kafka.
These are the most common Kafka reliability guarantees:
- Kafka guarantees the order of messages in a partition. If message A was written before message B, using the same producer in the same partition, then Kafka guarantees that the offset of message B will be higher than message A. This means that consumers will read message A before message B
- Messages are considered “committed” when they are written to the leader and all in-sync replicas (number of in-sync replicas and number of acks can be configured)
- Committed messages won’t be lost as long as at least one replica remains alive and retention policy holds
- Consumers can only read committed messages
- Kafka provides at-least-once message delivery semantics (doesn’t prevent duplicated messages being produced)
The important thing to note is that even though Kafka provides at-least-once delivery semantics, it does not provide exactly-once semantics and to achieve that we have to either rely on an external system with some support for unique keys or use Kafka Streams (0.11.0 release onwards).
Let’s also remember that even though these basic guarantees can be used to build a reliable system, there is much more to that. In Kafka, there is a lot of trade-offs involved in building a reliable system. The usual trade-offs are reliability and consistency versus availability, high throughput and low latency.
Why Kafka? Pros and Cons
Let’s review both the pros and cons of choosing Kafka.
Pros
- Tackles integration complexity
- Great tool for ETL or CDC
- Great for big data ingestion
- High throughput
- Disk-based retention
- Supports multiple producers/consumers
- Highly scalable
- Fault-tolerant
- Fairly low-latency
- Highly configurable
- Provides backpressure
Cons
- Requires a fair amount of time to understand and do not shoot yourself in the foot by accident
- Might not be the best solution for real low-latency systems
Kafka vs other messaging systems
A lot of things in Kafka were purposely named to resemble a JMS like messaging systems. This makes people wondering what the actual differences between Kafka and standard JMS systems like RabbitMQ or ActiveMQ are.
First of all the main difference is that Kafka consumers pull messages from the brokers which allow for buffering messages for as long as the retention period holds. In most other JMS systems, messages are actually pushed to the consumers instead. Pushing messages to the consumer makes things like backpressure really hard to achieve. Kafka also makes replaying of events easy as messages are stored on disk and can be replayed anytime (again within the limits of the retention period).
Besides that Kafka guarantees the ordering of messages within one partition and it provides an easy way for building scalable and fault-tolerant systems.
Summary
Time for a quick summary. In the era of ever-growing data and integration complexity, having a reliable and high-throughput messaging system that can be easily scaled is a must. Kafka seems to be one of the best available options that meet those criteria. It has been battle-tested for years by one of the biggest companies in the world.
We have to remember that Kafka is a fairly complex messaging system and there is a lot to learn to make full potential of it without shooting ourselves in the foot.
There are also multiple libraries and frameworks that make using Kafka even easier. Some of the most notable ones are Kafka Streams and Kafka Connect.
Extras
If you want to learn even more about Kafka, I can recommend the following book: “Kafka: The Definitive Guide”, which I found very useful.




{kind=link}
{kind=link}
{kind=link}