Introduction
When it comes to code compilation and execution, not all programming languages follow the same approach. One of the common although not ideal ways to differentiate them is to split them into 2 groups compiled and interpreted languages.
The main goal of both compilation and interpretation is to transform the human-readable source code into machine code that can be executed directly by a CPU, but there are some caveats to it.
One of the main things we have to understand is that a programming language itself is neither compiled nor interpreted, but the implementation of a programming language is. In fact, there are many programming languages that have been implemented using both compilers and interpreters.
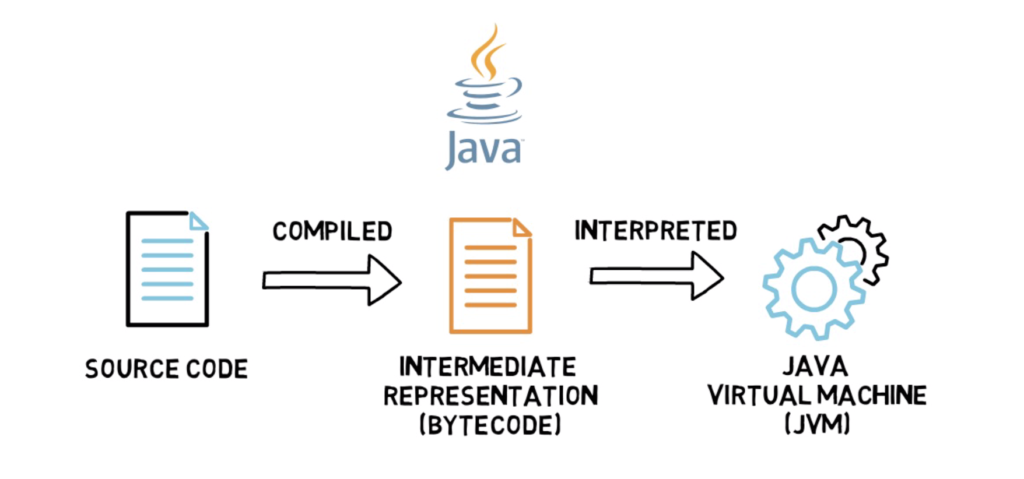
Java can be a good example of such a language as Java’s source code is compiled to an intermediate representation called bytecode and interpreted by Java’s interpreter that is a part of Java Virtual Machine (JVM). This is a standard process present in all of Java’s popular implementations.
Compiled Languages
A compiled language is a programming language that is typically implemented using compilers rather than interpreters. A compiler is a program that translates statements written in a particular programming language into another language usually machine code. A standard compiler instead of translating code on the fly does all of its work ahead of execution time.
A good example of a compiled language is C++.
In C++ the source code is compiled into machine code. The compilation process consists of preprocessing, compiling and linking, but the end result is either a library or an executable that can be executed directly by a CPU that the program was compiled for.
The main benefit of compiled languages is the speed of execution as the executable that contains machine code can be directly executed on the target machine without any additional steps.
The main drawbacks are poor portability as programs have to be compiled for a specific CPU architecture and a long time that is required for the actual compilation.
Other examples of popular compiled languages are C, Go, Haskell or Rust.
Interpreted Languages
An interpreted language is a programming language that is typically implemented using interpreters and doesn’t compile source code directly into machine code ahead of execution. The interpreter executes program translating each statement into a sequence of one or more subroutines and then into machine code. We can say that the interpreter translates programs on the fly instead of focusing on the whole program at once.
Even though interpreter could be translating source code into machine code, these days most of the interpreters work with an intermediate representation also called bytecode in most interpreted programming languages. This is because interpreting source code directly would be quite slow and most interpreted languages benefit from compiling into bytecode first that can prepare and optimise the code for further interpretation into machine code.
There are not many fully interpreted languages left. One noticeable example is Javascript that depending on the implementation can be fully interpreted. This means that the source code of the actual program would be interpreted by the interpreter and translated into machine code on the fly. This feature was quite useful in Javascript as the code could be easily sent over the network and executed in the user’s browser.
Even though it is quite hard to find any popular language in the fully interpreted language category, we can easily find plenty of them in the bytecode interpreted one. The examples are Java, C#, Python or Ruby.
The main benefits of using an interpreted language are portability as programs don’t have to be compiled for a specific CPU architecture and faster compilation process (for the language implementations that compile to bytecode).
The main drawbacks are usually slower execution speed and potential for leaking source code if the non-obfuscated source code is sent to the client.
Middle ground? JIT Compilation
So far it looks like both of the languages compiled and interpreted have their pros and cons.
What if I tell you you could still achieve the speed of a fully compiled language without sacrificing portability and faster compilation time? Sounds impossible? This is where JIT compilation comes to play.
JIT or just-in-time compilation is a hybrid between normal compilation also called ahead-of-time compilation and interpretation. Instead of translating each statement from the input file (which is usually bytecode), JIT has the ability to store already compiled machine code so it doesn’t have to translate it each time.
JIT compilation works by analysing the code that is being executed (usually bytecode) and making decisions which parts of the code should be fully compiled to machine code based on how often that piece of code is being executed (and a few other factors).
The main benefit of this approach is high execution speed as all the critical and often executed code fragments are fully compiled into machine code. This comes at a cost of a bit slower execution during the initial period when the critical code fragments are being analysed and are not fully compiled yet.
A full explanation of the JIT compilation process is outside of the scope of this video, but I’m thinking about creating another one dedicated to the JIT compilation as this is a super interesting process that not everyone fully understands.
Some of the languages that make use of JIT compilation are Java, C#, Pypy (alternative Python implementation) and V8 (Javascript engine).
Summary
Let’s compare a few main characteristics of compiled, interpreted and JIT-compiled languages one by one.
| compiled | interpreted | JIT-compiled | |
| execution speed | fast | slow | usually fast (depending on the JIT implementation) |
| portability | poor | good | good |
| compilation time | slow | fast (bytecode) | fast (bytecode) |
As you probably already noticed splitting programming languages into compiled and interpreted languages is quite artificial as there is not a lot of fully interpreted languages left.

Most of the popular programming languages these days fit into one of these three categories compiled, compiled to bytecode and interpreted and compiled to bytecode and interpreted with JIT compilation.
Extra
One more interesting fact before we wrap this up.
When it comes to programming languages with a multitude of different implementations, Python is one of the winners.
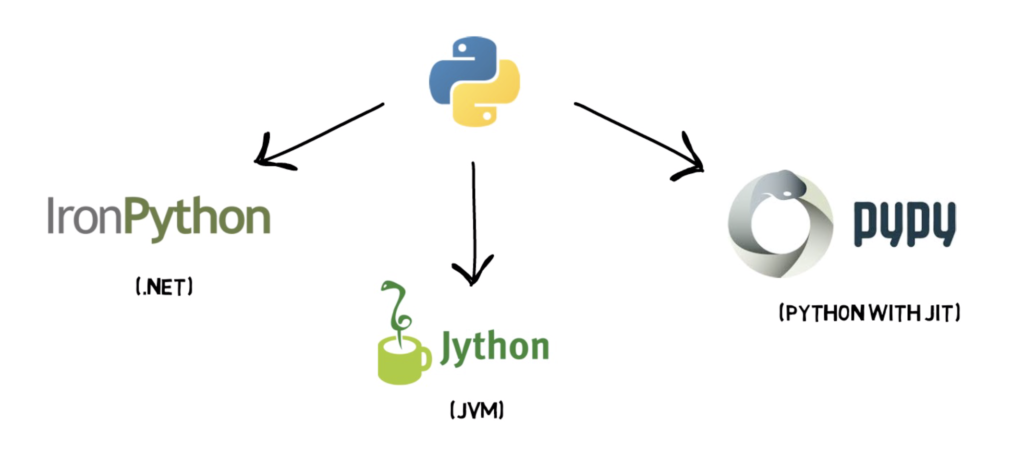
This is a non-exhaustive list of Python’s alternative implementations
- IronPython (Python running on .NET)
- Jython (Python running on the Java Virtual Machine)
- PyPy (Python with a JIT compiler)
If you have any questions about compiled and interpreted languages or any suggestions for the next videos please comment down below.



{kind=link}
{kind=link}
{kind=link}
One thought on “Compiled vs Interpreted Programming Languages – C, C++, Rust, Go, Haskell, C#, Java, Python, Ruby, Javascript”
Very well done and written!
I’ve just stareted bblogging myself just recently and noticed
thbat many writers simply rehash old ideas but add very little of worth.
It’s great to read an insightful write-upof some genuine value to your followers aand myself.
It is going on the list of factors I need to emulate as a new blogger.
Reader engagement and material value are king.
Many awesome ideas; you have unquestionably made it onn my list of sites to watch!
Keep up the fantastic work!
All the best,
Ailsun